
I am a professor for machine learning and data science at the University of Applied Sciences Berlin (HTW Berlin). My research activities span areas such as learning with limited data, building robust visual recognition models for quality control and medical image analysis, as well as combining annotation and learning workflows.
Previously, I was leading the machine learning team at the corporate research department of the ZEISS Group develop machine learning solutions for a wide range of products. Furthermore, I have been a lecturer in the computer vision group at the Friedrich Schiller University of Jena (Germany) leading the machine learning research activities and I worked as a PostDoc in the computer vision group of Trevor Darrell at ICSI/EECS (UC Berkeley, California).
Selected Publications
2026
|
Intelligence without intuition: a mixed-methods pilot study on reasoning models in musculoskeletal physiotherapy for low-back pain.
Frontiers in Digital Health. 1-18. 2026. 
 abstract
abstract
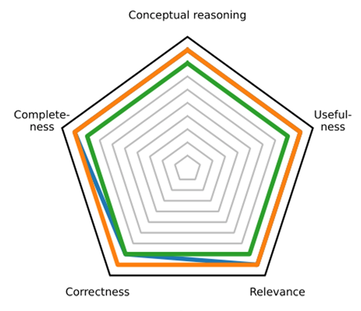
Abstract: Musculoskeletal pain, especially low-back pain, is highly prevalent and often challenging to manage due to its multifactorial nature. Effective diagnosis and therapy require clinicians to integrate biopsychosocial information within an evidence-based clinical reasoning framework. Large language models that ``think'' before responding, so-called reasoning models, show promise to support such complex decision-making, yet their validity and reliability in this setting remain unclear. In our work, we present a comprehensive human evaluation of reasoning models for clinical reasoning. Our results indicate that state-of-the-art reasoning models demonstrate sufficient test-retest reliability and are competent or proficient in terms of their conceptual reasoning, completeness, correctness, relevance, and usefulness, with no statistically significant or clinically relevant differences between them. However, our qualitative analysis reveals weaknesses in logical coherence, patient-centeredness, empathy, and intuition, with most deviations from expert reasoning in the domain of intuition. Our findings underscore the importance of adopting a multidimensional framework for evaluating language model outputs and allow us to provide guidance for model selection and prompting strategies to enhance clinical reasoning performance. 
@article{Knauer2026Intuition,
author = {Knauer, Ricardo and Kalmring, Matthias and Rodner, Erik},
title = {Intelligence without intuition: a mixed-methods pilot study on reasoning models in musculoskeletal physiotherapy for low-back pain},
journal = {Frontiers in Digital Health},
year = {2026},
volume = {8},
pages = {1-18},
doi = {10.3389/fdgth.2026.1789412},
}
|

|
Synthetic data enables human-grade microtubule analysis with foundation models for segmentation.
PLOS Computational Biology. 2026.
 abstract
abstract
Abstract: Studying microtubules (MTs) and their mechanical properties is central to understanding intracellular transport, cell division, and drug action. While important, experts still need to spend many hours manually segmenting these filamentous structures. The suitability of state-of-the-art methods for this task cannot be systematically assessed, as large-scale labeled datasets are missing. We address this gap by introducing the synthetic dataset SynthMT, produced by tuning a novel image generation pipeline on real-world interference reflection microscopy (IRM) frames of in vitro reconstituted MTs without requiring human annotations. In our benchmark, we evaluate nine fully automated methods for MT analysis in both zero- and Hyperparameter Optimization (HPO)-based few-shot settings. Across both settings, classical algorithms and current foundation models still struggle to achieve the accuracy required for biological downstream analysis on in vitro MT IRM images that humans perceive as visually simple. However, a notable exception is the recently introduced SAM3 model. After HPO on only ten random SynthMT images, its text-prompted version SAM3Text achieves near-perfect and in some cases super-human performance on unseen, real data. This indicates that fully automated MT segmentation has become feasible when method configuration is effectively guided by synthetic data. To enable progress, we publicly release the dataset, the generation pipeline, and the evaluation framework.
@article{Koddenbrock2026Microtubule,
author = {Koddenbrock, Mario and Westerhoff, Justus and Fachet, Daniel and Reber, Stefan and Gers, Felix A. and Rodner, Erik},
title = {Synthetic data enables human-grade microtubule analysis with foundation models for segmentation},
journal = {PLOS Computational Biology},
year = {2026},
doi = {10.1371/journal.pcbi.1013901},
}
|
|
RamanBench: A Large-Scale Benchmark for Machine Learning on Raman Spectroscopy.
arXiv preprint arXiv:2605.02003. 2026. preprint
abstract
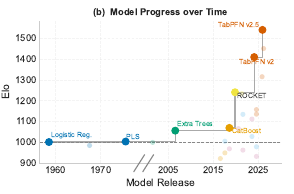
Abstract: Machine Learning (ML) has transformed many scientific fields, yet key applications still lack standardized benchmarks. Raman spectroscopy, a widely used technique for non-invasive molecular analysis, is one such field where progress is limited by fragmented datasets, inconsistent evaluation, and models that fail to capture the structure of spectral data. We introduce RamanBench, the first large-scale, fully reproducible benchmark for ML on Raman spectroscopy, consisting of streamlined data access, evaluation protocols and code, as well as a live leaderboard. It unifies 74 datasets (including 16 first released with this benchmark) across four domains, comprising 325,668 spectra and spanning classification and regression tasks under diverse experimental conditions. We benchmark 28 models under a standardized protocol, including classical methods (e.g., PLS), Raman-specific (e.g., RamanNet), Tabular Foundation Model (TFM) (e.g., TabPFN), and time-series approaches (e.g., ROCKET). TFM consistently outperform domain-specific and gradient boosting baselines, while time-series models remain competitive. However, no method generalizes across datasets, revealing a fundamental gap. Therefore, we invite the community to contribute new approaches to our living benchmark, with the potential to accelerate advances in critical applications such as medical diagnostics, biological research, and materials science.
@article{Koddenbrock2026Raman,
author = {Koddenbrock, Mario and Lange, Christoph and Legner, Robin and Jäger, Martin and Kögler, Martin and Cruz Bournazou, Mariano N. and Neubauer, Peter and Biessmann, Felix and Rodner, Erik},
title = {RamanBench: A Large-Scale Benchmark for Machine Learning on Raman Spectroscopy},
journal = {arXiv preprint arXiv:2605.02003},
year = {2026},
}
|
|
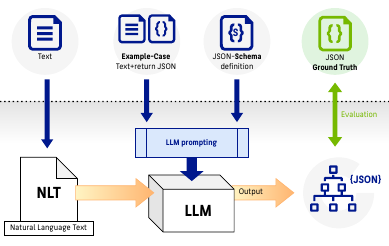
LLMStructBench: Benchmarking Large Language Model Structured Data Extraction.
arXiv preprint arXiv:2602.14743. 2026. preprint
abstract
Abstract: We present LLMStructBench, a novel benchmark for evaluating Large Language Models (LLMs) on extracting structured data and generating valid JavaScript Object Notation (JSON) outputs from natural-language text. Our open dataset comprises diverse, manually verified parsing scenarios of varying complexity and enables systematic testing across 22 models and five prompting strategies. We further introduce complementary performance metrics that capture both token-level accuracy and document-level validity, facilitating rigorous comparison of model, size, and prompting effects on parsing reliability. In particular, we show that choosing the right prompting strategy is more important than standard attributes such as model size. This especially ensures structural validity for smaller or less reliable models but increases the number of semantic errors. Our benchmark suite is a step towards future research in the area of LLM applied to parsing or Extract, Transform and Load (ETL) applications.
@article{Tenckhoff2026,
author = {Tenckhoff, Sönke and Koddenbrock, Mario and Rodner, Erik},
title = {LLMStructBench: Benchmarking Large Language Model Structured Data Extraction},
journal = {arXiv preprint arXiv:2602.14743},
year = {2026},
}
|
2025
|
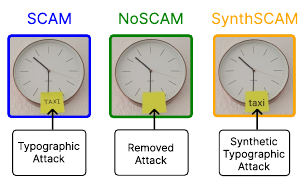
SCAM: A Real-World Typographic Robustness Evaluation for Multimodal Foundation Models.
CVPR 2025 Workshop on Evaluating Foundation Models (EVAL-FoMo-2). 1-22. 2025.
abstract
Abstract: Typographic attacks exploit the interplay between text and visual content in multimodal foundation models, causing misclassifications when misleading text is embedded within images. Existing datasets are limited in size and diversity, making it difficult to study such vulnerabilities. In this paper, we introduce SCAM, the largest and most diverse dataset of real-world typographic attack images to date, containing 1162 images across hundreds of object categories and attack words. Through extensive benchmarking of Vision-Language Models on SCAM, we demonstrate that typographic attacks significantly degrade performance, and identify that training data and model architecture influence the susceptibility to these attacks. Our findings indicate that typographic attacks remain effective against state-of-the-art Large Vision-Language Models, especially those employing vision encoders inherently vulnerable to such attacks. However, employing larger Large Language Model backbones reduces this vulnerability while simultaneously enhancing typographic understanding. Additionally, we demonstrate that synthetic attacks closely resemble real-world (handwritten) attacks, validating their use in research. Our work provides a comprehensive resource and empirical insights to facilitate future research toward robust and trustworthy multimodal AI systems. Finally, we publicly release the datasets introduced in this paper, along with the code for evaluations under http://www.bliss.berlin/research/scam.
@inproceedings{Westerhoff2025Scam,
author = {Westerhoff, Justus and Purelku, Erblina and Hackstein, Jakob and Loos, Jonas and Pinetzki, Leo and Rodner, Erik and Hufe, Lorenz},
title = {SCAM: A Real-World Typographic Robustness Evaluation for Multimodal Foundation Models},
booktitle = {CVPR 2025 Workshop on Evaluating Foundation Models (EVAL-FoMo-2)},
year = {2025},
pages = {1-22},
}
|
|
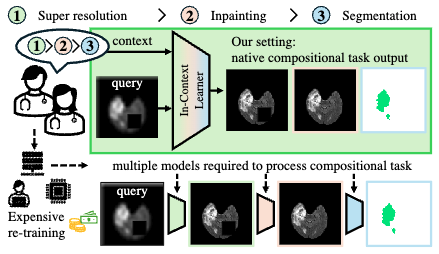
Is Visual in-Context Learning for Compositional Medical Tasks within Reach?.
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2642-2652. 2025.
@inproceedings{Reiss2025,
title = {Is Visual in-Context Learning for Compositional Medical Tasks within Reach?},
author = {Reiß, Simon and Marinov, Zdravko and Jaus, Alexander and Seibold, Constantin and Sarfraz, M Saquib and Rodner, Erik and Stiefelhagen, Rainer},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
pages = {2642--2652},
year = {2025},
}
|
|
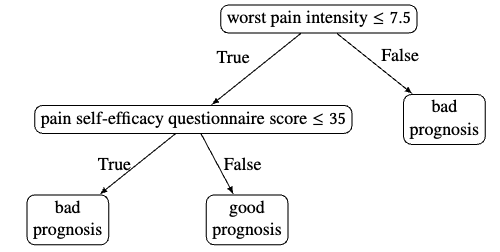
`Oh LLM, I'm Asking Thee, Please Give Me a Decision Tree': Zero-Shot Decision Tree Induction and Embedding with Large Language Models.
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2. 1196-1206. 2025.
@inproceedings{Knauer2025KDD,
author = {Knauer, Ricardo and Koddenbrock, Mario and Wallsberger, Raphael and Brisson, Nicholas M. and Duda, Georg N. and Falla, Deborah and Evans, David W. and Rodner, Erik},
title = {`Oh LLM, I'm Asking Thee, Please Give Me a Decision Tree': Zero-Shot Decision Tree Induction and Embedding with Large Language Models},
booktitle = {Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2},
year = {2025},
pages = {1196-1206},
doi = {10.1145/3711896.3736818},
}
|
2023

|
CAD Models to Real-World Images: A Practical Approach to Unsupervised Domain Adaptation in Industrial Object Classification.
European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), Workshop Adapting to Change: Reliable Learning Across Domains. 2023.
@inproceedings{ritter2023cad,
title = {CAD Models to Real-World Images: A Practical Approach to Unsupervised Domain Adaptation in Industrial Object Classification},
author = {Ritter, Dennis and Hemberger, Mike and Hönig, Marc and Stopp, Volker and Rodner, Erik and Hildebrand, Kristian},
booktitle = {European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), Workshop Adapting to Change: Reliable Learning Across Domains},
year = {2023},
doi = {https://doi.org/10.48550/arXiv.2310.04757},
}
|

|
Decoupled Semantic Prototypes enable learning from diverse annotation types for semi-weakly segmentation in expert-driven domains.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 15495-15506. 2023.
@inproceedings{reiss2023decoupled,
title = {Decoupled Semantic Prototypes enable learning from diverse annotation types for semi-weakly segmentation in expert-driven domains},
author = {Reiß, Simon and Seibold, Constantin and Freytag, Alexander and Rodner, Erik and Stiefelhagen, Rainer},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
pages = {15495--15506},
doi = {10.1109/CVPR52729.2023.01487},
year = {2023},
}
|
2022
|
Graph-constrained contrastive regularization for semi-weakly volumetric segmentation.
European Conference on Computer Vision (ECCV). 401-419. 2022.
@inproceedings{reiss2022graph,
title = {Graph-constrained contrastive regularization for semi-weakly volumetric segmentation},
author = {Reiß, Simon and Seibold, Constantin and Freytag, Alexander and Rodner, Erik and Stiefelhagen, Rainer},
booktitle = {European Conference on Computer Vision (ECCV)},
volume = {13681},
pages = {401--419},
year = {2022},
doi = {10.1007/978-3-031-19803-8_24},
}
|
2021
|
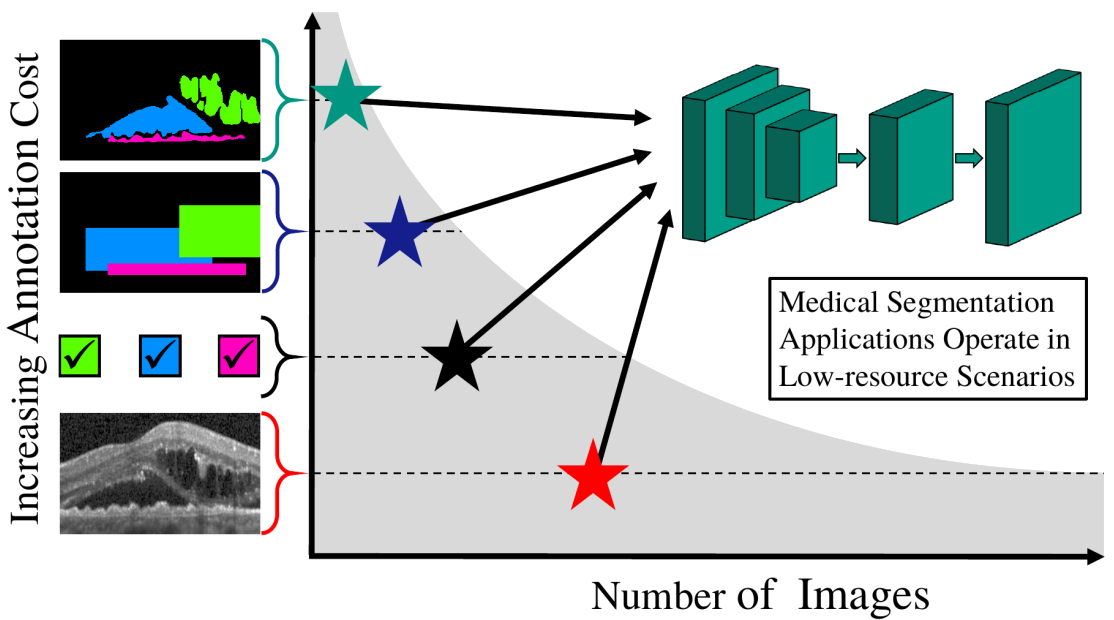
Every annotation counts: Multi-label deep supervision for medical image segmentation.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 9532-9542. 2021.
@inproceedings{reiss2021every,
title = {Every annotation counts: Multi-label deep supervision for medical image segmentation},
author = {Reiß, Simon and Seibold, Constantin and Freytag, Alexander and Rodner, Erik and Stiefelhagen, Rainer},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
pages = {9532--9542},
doi = {10.1109/CVPR46437.2021.00941},
year = {2021},
}
|
2020

|
The whole is more than its parts? From explicit to implicit pose normalization.
IEEE Transactions on Pattern Analysis and Machine Intelligence. 42(3): 749-763. 2020.
abstract
Abstract: Fine-grained classification describes the automated recognition of visually similar object categories like birds species. Previous works were usually based on explicit pose normalization, i.e., the detection and description of object parts. However, recent models based on a final global average or bilinear pooling have achieved a comparable accuracy without this concept. In this paper, we analyze the advantages of these approaches over generic CNNs and explicit pose normalization approaches. We also show how they can achieve an implicit normalization of the object pose. A novel visualization technique called activation flow is introduced to investigate limitations in pose handling in traditional CNNs like AlexNet and VGG. Afterward, we present and compare the explicit pose normalization approach neural activation constellations and a generalized framework for the final global average and bilinear pooling called α-pooling. We observe that the latter often achieves a higher accuracy improving common CNN models by up to 22.9%, but lacks the interpretability of the explicit approaches. We present a visualization approach for understanding and analyzing predictions of the model to address this issue. Furthermore, we show that our approaches for fine-grained recognition are beneficial for other fields like action recognition.
@article{Simon19_Implicit,
author = {Marcel Simon and Erik Rodner and Trevor Darell and Joachim Denzler},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
title = {The whole is more than its parts? From explicit to implicit pose normalization},
year = {2020},
volume = {42},
number = {3},
pages = {749-763},
doi = {10.1109/TPAMI.2018.2885764},
}
|
2019

|
Fully Convolutional Networks in Multimodal Nonlinear Microscopy Images for Automated Detection of Head and Neck Carcinoma: A Pilot Study.
Head and Neck. 41(1): 116-121. 2019.
abstract
Abstract: A fully convolutional neural networks (FCN)-based automated image analysis algorithm to discriminate between head and neck cancer and noncancerous epithelium based on nonlinear microscopic images was developed. Head and neck cancer sections were used for standard histopathology and co-registered with multimodal images from the same sections using the combination of coherent anti-Stokes Raman scattering, two-photon excited fluorescence, and second harmonic generation microscopy. The images analyzed with semantic segmentation using a FCN for four classes: cancer, normal epithelium, background, and other tissue types. A total of 114 images of 12 patients were analyzed. Using a patch score aggregation, the average recognition rate and an overall recognition rate or the four classes were 88.9\% and 86.7\%, respectively. A total of 113 seconds were needed to process a whole-slice image in the dataset. Multimodal nonlinear microscopy in combination with automated image analysis using FCN seems to be a promising technique for objective differentiation between head and neck cancer and noncancerous epithelium.
@article{Rodner19_Fully,
author = {Erik Rodner and Thomas Bocklitz and Ferdinand von Eggeling and Günther Ernst and Olga Chernavskaia and Jürgen Popp and Joachim Denzler and Orlando Guntinas-Lichius},
title = {Fully Convolutional Networks in Multimodal Nonlinear Microscopy Images for Automated Detection of Head and Neck Carcinoma: A Pilot Study},
journal = {Head and Neck},
year = {2019},
volume = {41},
number = {1},
pages = {116--121},
doi = {10.1002/hed.25489},
}
|
|
Detecting Regions of Maximal Divergence for Spatio-Temporal Anomaly Detection.
IEEE Transactions on Pattern Analysis and Machine Intelligence. 41(5): 1088-1101. 2019. (Pre-print published in 2018.)
abstract
Abstract: Automatic detection of anomalies in space- and time-varying measurements is an important tool in several fields, e.g., fraud detection, climate analysis, or healthcare monitoring. We present an algorithm for detecting anomalous regions in multivariate spatio-temporal time-series, which allows for spotting the interesting parts in large amounts of data, including video and text data. In opposition to existing techniques for detecting isolated anomalous data points, we propose the "Maximally Divergent Intervals" (MDI) framework for unsupervised detection of coherent spatial regions and time intervals characterized by a high Kullback-Leibler divergence compared with all other data given. In this regard, we define an unbiased Kullback-Leibler divergence that allows for ranking regions of different size and show how to enable the algorithm to run on large-scale data sets in reasonable time using an interval proposal technique. Experiments on both synthetic and real data from various domains, such as climate analysis, video surveillance, and text forensics, demonstrate that our method is widely applicable and a valuable tool for finding interesting events in different types of data.
@article{Barz18_MDI,
title = {Detecting Regions of Maximal Divergence for Spatio-Temporal Anomaly Detection},
author = {Björn Barz and Erik Rodner and Yanira Guanche Garcia and Joachim Denzler},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
year = {2019},
volume = {41},
number = {5},
pages = {1088--1101},
doi = {10.1109/TPAMI.2018.2823766},
}
|
2018
|
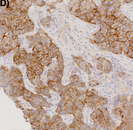
HER2 challenge contest: a detailed assessment of automated HER2 scoring algorithms in whole slide images of breast cancer tissues.
Histopathology. 72(2): 227-238. 2018.
abstract
Abstract: Aims Evaluating expression of the human epidermal growth factor receptor 2 (HER2) by visual examination of immunohistochemistry (IHC) on invasive breast cancer (BCa) is a key part of the diagnostic assessment of BCa due to its recognized importance as a predictive and prognostic marker in clinical practice. However, visual scoring of HER2 is subjective, and consequently prone to interobserver variability. Given the prognostic and therapeutic implications of HER2 scoring, a more objective method is required. In this paper, we report on a recent automated HER2 scoring contest, held in conjunction with the annual PathSoc meeting held in Nottingham in June 2016, aimed at systematically comparing and advancing the state-of-the-art artificial intelligence (AI)-based automated methods for HER2 scoring. Methods and results The contest data set comprised digitized whole slide images (WSI) of sections from 86 cases of invasive breast carcinoma stained with both haematoxylin and eosin (H&E) and IHC for HER2. The contesting algorithms predicted scores of the IHC slides automatically for an unseen subset of the data set and the predicted scores were compared with the ‘ground truth’ (a consensus score from at least two experts). We also report on a simple ‘Man versus Machine’ contest for the scoring of HER2 and show that the automated methods could beat the pathology experts on this contest data set. Conclusions This paper presents a benchmark for comparing the performance of automated algorithms for scoring of HER2. It also demonstrates the enormous potential of automated algorithms in assisting the pathologist with objective IHC scoring.
@article{Qaiser18_HIS,
author = {Talha Qaiser and Abhik Mukherjee and Chaitanya Reddy PB and Sai D Munugoti and Vamsi Tallam and Tomi Pitkäaho and Taina Lehtimäki and Thomas Naughton and Matt Berseth and AnÃbal Pedraza and Ramakrishnan Mukundan and Matthew Smith and Abhir Bhalerao and Erik Rodner and Marcel Simon and Joachim Denzler and Chao-Hui Huang and Gloria Bueno and David Snead and Ian O Ellis and Mohammad Ilyas and Nasir Rajpoot},
journal = {Histopathology},
title = {HER2 challenge contest: a detailed assessment of automated HER2 scoring algorithms in whole slide images of breast cancer tissues},
year = {2018},
number = {2},
pages = {227--238},
volume = {72},
doi = {10.1111/his.13333},
}
|

|
Active Learning for Regression Tasks with Expected Model Output Changes.
British Machine Vision Conference (BMVC). 2018.
abstract
Abstract: Annotated training data is the enabler for supervised learning. While recording data at large scale is possible in some application domains, collecting reliable annotations is time-consuming, costly, and often a project's bottleneck. Active learning aims at reducing the annotation effort. While this field has been studied extensively for classification tasks, it has received less attention for regression problems although the annotation cost is often even higher. We aim at closing this gap and propose an active learning approach to enable regression applications. To address continuous outputs, we build on Gaussian process models -- an established tool to tackle even non-linear regression problems. For active learning, we extend the expected model output change (EMOC) framework to continuous label spaces and show that the involved marginalizations can be solved in closed-form. This mitigates one of the major drawbacks of the EMOC principle. We empirically analyze our approach in a variety of application scenarios. In summary, we observe that our approach can efficiently guide the annotation process and leads to better models in shorter time and at lower costs.
@inproceedings{Kaeding18_ALR,
author = {Christoph Käding and Erik Rodner and Alexander Freytag and Oliver Mothes and Björn Barz and Joachim Denzler},
booktitle = {British Machine Vision Conference (BMVC)},
title = {Active Learning for Regression Tasks with Expected Model Output Changes},
year = {2018},
}
|